Indexation Google : Problème et solutions
Depuis plusieurs mois, la plupart des webmasters rencontrent des problèmes pour indexer leur page dans Google. Que ce soit pour un nouveau site ou juste la création de nouvelles pages, Google refuse d'indexer ces pages ou si vous avez de la chance il les indexe mais cela prend du temps. Nous allons voir pourquoi Google n'indexe pas vos pages et les solutions qui peuvent être mises en place.
Pourquoi Google n'indexe pas mes pages ?
Tout d'abord, il faut distinguer 2 choses. Les URLs qui ne sont pas indexées car un ou plusieurs facteurs bloquent son indexation et le fait que Google fait le choix de ne pas indexer votre page car il ne la juge pas assez qualitative.
Google reconnait qu'il y a des problèmes d'indexation et il vient de communiquer sur le sujet en donnant un peu plus d'explications (source en anglais) sans rentrer dans le détail.
"Il est théoriquement impossible de tout crawler, puisque le nombre d'URL réelles est effectivement infini. Comme personne ne peut se permettre de conserver un nombre infini d'URL dans une base de données, tous les robots d'exploration du Web font des hypothèses, des simplifications et des suppositions sur ce qui vaut vraiment la peine d'être exploré."
Par rapport à ce qui est dit, quand on est Google, j'ai du mal à voir comment ils peuvent avoir ce type de problème (crawl et stockage). La seule raison évidente et qui est également spécifiée c'est qu'il souhaite fournir un index sans déchet (pages spammées, pages inutiles...) pour fournir des pages uniquement pertinentes et surtout réduire la force de certaines tactiques de netlinking.
Comment cela se traduit ?
En vous connectant sur le compte Google Search Console de votre site, dans la section Index > Couverture > Exclues, vous aurez un tableau qui liste les différents problèmes liés aux URLs qui ne sont pas indexées. Ce qui concerne la problématique d'indexation du moment, ceux sont les types "Détectée, actuellement non indexée" et "Explorée, actuellement non indexée". Dans l'un des cas, il connait l'URL mais il ne l'a pas encore crawlé, dans l'autre cas, il l'a crawlé mais n'a pas jugé bon de l'indexer (cela peut être temporaire).
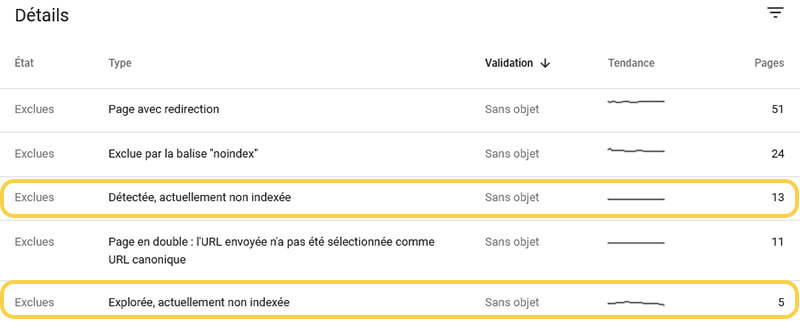
Pour Google, il y a donc un problème au niveau du crawl, votre nouvelle URL peut ne pas être crawlée par Google, et par conséquent, elle ne pourra pas être indexée. Mais il y a également un problème au niveau de l'indexation pour un souci de stockage des données.
Google ne communique pas sur les critères qu'il utilise pour déterminer quel site il doit crawler ou quelle page il doit indexer. Cependant, Google souhaite favoriser les pages de qualité au détriment des pages déchets (spam, contenu inutile...). On peut donc penser que Google va donc favoriser des sites ayant une certaine popularité à ces yeux afin de les crawler et indexer les URLs qui possèdent un contenu utile. Cela peut donc être problématique pour un nouveau site qui n'a aucune popularité.
Les éléments qui peuvent empêcher l'indexation d'une URL
Si votre site ou des nouvelles pages que vous avez créé ne s'indexent pas, je vous invite dans un premier temps à vérifier les éléments suivants :
Vérifier le contenu du fichier robots.txt : Ce fichier est présent à la racine du site et indique par des instructions quelles sont les URLs qui peuvent être crawlées ou non par les robots des moteurs de recherche.
Si l'instruction suivante est présente dans le robots.txt, Google ne va pas parcourir le contenu de vos pages et donc votre site ne pourra pas être indexé.
Disallow: /Il peut également y avoir une instruction spécifique qui va exclure un pattern d'URLs. Il faut donc vérifier tous les éléments "Disallow". Pour faciliter cette vérification, vous pouvez également tester votre URL avec l'inspecteur d'URL de la Search Console ou l'outil de test du robots.txt. Ces outils vous indiqueront si l'URL est bloquée par le robots.txt.
La Meta Robots Noindex : La balise Meta Robots permet également de données des instructions aux crawlers des moteurs de recherche. On peut notamment indiquer à Google de ne pas suivre les liens présents dans la page (nofollow) ou ne pas indexer l'URL (noindex).
Si l'instrucion noindex est présente dans la balise Meta Robots dans l'entête HTML de l'URL que vous souhaitez indexer, alors vous indiquez aux moteurs de recherche de ne pas indexer la page. Il s'agit d'un problème qui peut arriver lors d'une mise en ligne d'un nouveau site. Le mieux est de supprimer toute la balise de l'entête HTML de votre page.
<meta name="robots" content="noindex">L'instruction noindex peut également être définie dans l'entête HTTP des pages via X-Robots-Tag. Il faut donc veiller à checker l'entête HTTP de l'URL pour vérifier que cette instruction n'est pas présente.
Les URLs canoniques : Une mauvaise utilisation des URLs canoniques peut également entrainer des soucis pour l'indexation de vos pages.
En effet, si l'URL canonique implémentée pointent vers une autre URL du site ou bien même vers un autre site. Google ne la prendra pas en compte dans son index. Il faut donc vérifier dans l'entête HTML de la page que l'URL renseignée dans la balise Link rel="canonical" est la bonne. Attention, une URL canonique peut également être définie via l'entête HTTP.
Contenu de mauvaise qualité : Un contenu de mauvaise qualité est un contenu qui duplique une autre page (interne ou externe au site) ou dont le contenu est très proche. Pour citer Google, cela peut également être un contenu qui n'apporte rien par rapport à ce qu'il y a déjà sur d'autres sites Internet. Enfin, si vos pages ont peu voire pas de contenu, là encore Google n'indexera pas vos pages.
On peut également citer les pages dont le contenu n'est pas accessible pour le moteur :
- contenu présent dans une image sans alternative
- contenu écrit en JavaScript
- utilisation de frame (iframe)
- contenu accessible uniquement si les cookies sont activés
Google peut crawler ces URLs mais ne pas les indexer car il les jugera comme non pertinentes.
Le maillage interne : Si au sein de votre maillage interne, des pages ne recoivent que très peu de liens voire pas du tout (page orpheline), dans ce cas Google ne va sans doute pas les indexer, ou mettre du temps à le faire.
Également, si une page est accessible à un niveau de profondeur important (nombre de clic depuis la page d'accueil), cela peut freiner l'indexation de ces URLs.
Enfin, vérifier en crawlant votre site qu'il n'y a pas de problèmes qui pourraient freiner la progression des robots des moteurs de recherche (pages inutiles, pages en erreur, pages redirigées...).
Il est donc important de regarder le nombre de liens et comment vos URLs sont liées depuis votre site.
Vous rencontrez des problèmes d'indexation avec Google ? N'hésitez pas à me contacter.
Contactez-moiSolutions pour indexer une URL dans Google
Après avoir vérifié qu'aucun des éléments ci-dessus ne bloque ou freine l'indexation des pages de votre site. Voici plusieurs solutions qui permettent de favoriser l'indexation de vos pages.
Utiliser Google Search Console
Google a mis à disposition des webmasters, Google Search Console, un outil pour visualiser des données SEO de votre site mais également pour favoriser et suivre l'indexation de votre site.
Soumettre un fichier Sitemap XML
Pour favoriser l'indexation des vos URLs, le classique fichier Sitemap XML, qui liste les URLs d'un site à indexer, peut être soumis via la Search Console. Il vous suffit de vous rendre dans la section "Index > Sitemaps", de renseigner l'URL du Sitemap XML ou de l'index de Sitemap et d'envoyer l'information à Google.
Comment soumettre une URL à Google ?
Google Search Console vous permet également d'inspecter une URL et de la soumettre à l'indexation.
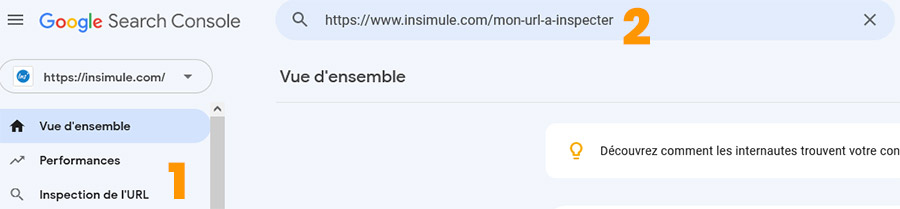
- Cliquez sur "Inspection de l'URL"
- Remplissez le champ avec l'URL à indexer
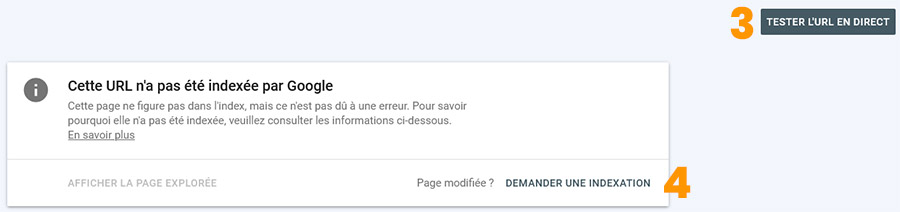
- Cliquez sur "Test l'URL en direct"
- Une fois le test effectué et que Google indique que la page peut être indexée, cliquez sur "Demander une indexation"
Utiliser les API Google
Cela peut paraitre compliqué au départ, mais en suivant les instructions vous ne devriez pas rencontrer de problème.
Google Indexing API
Un autre moyen d'inviter Google sur votre site est d'utiliser l'API Google Indexing, elle vous permettra de soumettre à Google plusieurs URLs à la fois, le quota est de 200 URLs par jour.
J'utilise personnellement cette solution avec Node JS et cela fonctionne plutôt bien. Vous trouverez le code ici afin de tester cette solution.
Google Inspection API
Sortie début janvier 2022, Google Inspection API permet à la fois de soumettre des URLs à Google et également de vérifier si des URLs sont indexées dans le moteur de recherche. Il s'agit en fait de la même chose que l'outil d'inspection disponible dans Google Search Console. Voici également la marche à suivre pour tester cette solution avec Node JS.
Outils pour forcer l'indexation sur Google
Avec les problèmes liés à l'indexation des URLs sur Google, plusieurs outils ont vu le jour et garantissent une indexation à 80% sur 24h. Si l'indexation ne fonctionne pas au bout de 10 jours pour certaines URLs, vous serez recrédité.
C'est le cas de l'outil IndexMeNow créé par Stéphane Madaleno. Si vous avez écumé tous les moyens gratuits pour essayer d'indexer vos URLs et que cela ne fonctionne toujours pas, il ne vous reste plus qu'à tester l'outil.
Autres solutions pour indexer vos pages
Si vous rencontrez des problèmes d'indexation bien qu'aucun blocage n'ait été relevé, voici d'autres solutions à mettre en place :
- Créer des backlinks vers les URLs à indexer.
- Modifier le TITLE et/ou H1 et/ou le contenu de la page.
- Augmenter le nombre de liens internes vers l'URL.
- Utiliser un service de Google pour faire venir le robot d'exploration de Google sur votre page.
- Partager l'URL sur les réseaux sociaux.
Comment savoir si une URL ou un site est indexé par Google ?
Dans Google Search Console
Tout d'abord, grâce à Google Search Console, vous pouvez voir si une URL est indexée en inspectant l'URL : "Inspection de l'URL". Google vous indiquera si l'URL testée est indexée.
Toujours dans Google Search Console, en vérifiant si votre URL est listée dans la partie "Index > Couverture > Valides".
Avec des commandes Google
En tapant dans la barre de recherche Google, le classique "site:votredomain", vous aurez la liste des pages que Google à indexer. Vous pouvez également le faire avec une URL spécifique mais ce n'est pas toujours fiable, par exemple, cela ne fonctionnera pas une URL possédant des paramètres.
Pour tester une URL en particulier, vous pouvez utiliser les commandes "info:votreurl" ou alors "inurl:votreurl". Vous pourrez donc voir si Google a bien indexé votre page.
Outils pour checker l'indexation Google
Il y a des outils et des sites qui vous permettent de fournir une liste d'URLs afin de voir si celles-ci sont indexées par Google, en voici quelques un :
- Screaming Frog SEO : Depuis la version 16.6, vous avez la possibilité de checker si vos pages sont indexées.
- Check-position : L'outil qui permet déjà de suivre le positionnement de sites gratuitement sur 200 mots-clés, vous offre également la possibilité de vérifier l'indexation Google de 200 URLs. Cet outil ne nécessite pas d'être propriétaire du site pour tester l'indexation contraitement aux autres outils listés.
- Valentin.app : Sur le même modèle que check-position (moins beau quand même :)), Valentin.app, avec son Google Bulk Inspect URLs, vous permet également de checker l'indexation de vos URLs.
D'autres solutions existent comme vous en trouverez dans l'article de Search Engine Land.
N'hésitez pas à me contacter via le site, Twitter ou LinkedIn si vous avez d'autres solutions pour indexer, favoriser l'indexation d'URL ou pour échanger sur le sujet.

Consultant SEO senior
Plus de 17 ans d'expérience en SEO.
Passage en agence, chez l'annonceur et en freelance
➔ Discutons de votre projet
Retrouvez-moi également sur LinkedIn et Twitter. Je partage également de petits outils SEO pour vous aider dans le traitement, l'analyse de données et dans vos tâches quotidiennes.